martin
Pytorch学习率调整策略
import torch
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
model = AlexNet(num_classes=10)
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
x = list(range(100))
y = []
for epoch in range(100):
optimizer.step()
scheduler.step() # 更新一次学习率
y.appen(schedular.get_lr()[0])
# optimizer.state_dict()['param_groups'][0]['lr'] # 也可以获取当区学习率
plt.plot(x, y)
plt.show()
-
自定义调整
LambdaLR- 自定义函数
lambda1 = lambda epoch: epoch // 30 # epoch//30 * init_lr(0.05) lambda2 = lambda epoch: 0.95 ** epoch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda= lambda2)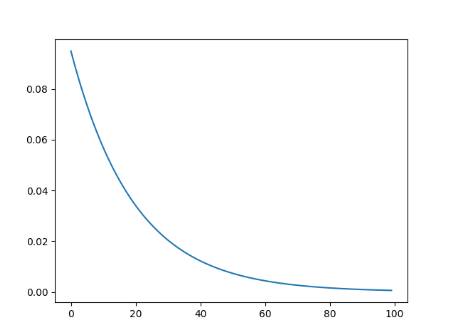
- 循环中更改
for epoch in range(100): optimizer.step() if epoch % 5 == 0: for params in optimizer.param_groups: params['lr'] *= 0.8 # 将该组参数的学习率 * 0.9 # params['weight_decay'] = 0.5 # 当然也可以修改其他属性
-
阶梯递降
StepLR:需要指定[step_size,gamma, last_epoch],step_size为下降频率,gamma为decay衰减系数, last_epoch上一个学习率 -1代表初始值 MultiStepLR:则指定一个step_list,每个指定的step则乘以gamma衰减系数,milestones=[30,60,80]
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.5, last_epoch=-1)

scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30,60,80],gamma=0.5)

-
指数衰减
gamma是衰减系数,越大衰减的越慢
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
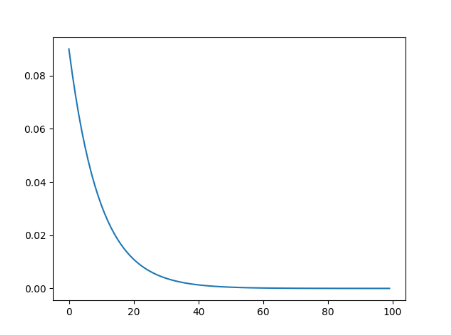
- 余弦退火
T_max: 每次cosine的epoch数,既cos函数周期 eta_min: 每个周期衰减的最小学习率,一般设置为1e-5之类的小学习率 注意,这只实现了SGDR的余弦退火部分,而没有重新启动
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min = 1e-5)
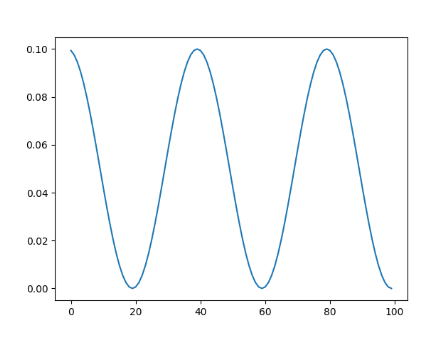
-
热启动余弦退火
带热启动的余弦退火 T_0:第一次重启的迭代次数 T_mult:增大周期
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=2, eta_min = 1e-5)
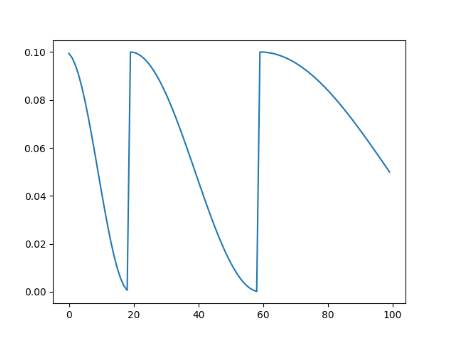
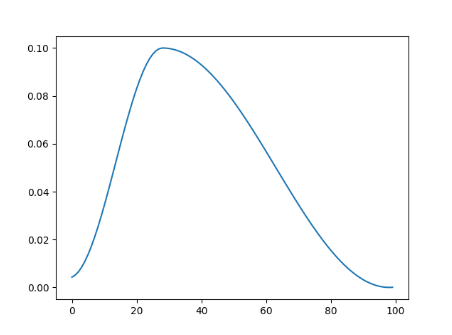
- 第一次退火到大学习率
将学习率从一个初始学习率退火到一个最大学习率,然后从这个最大学习率退火到一个比初始学 习率低很多的最小学习率
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, steps_per_epoch=10, epochs=10)
- 自适应下降
当loss不减时降低学习率 这个调度器读取一个指标数量,如果没有看到“容忍间隔”时间内的改善,学习率就会降低 factor:衰减因子 $lr=lr*fator$ patience:容忍epoch间隔,当patience个epoch损失没有改进时使学习率会降低。
# ReduceLROnPlateau没有get_lr()
# 使用 optimizer.state_dict()['param_groups'][0]['lr'] 获取当前学习率
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.1, patience=3)

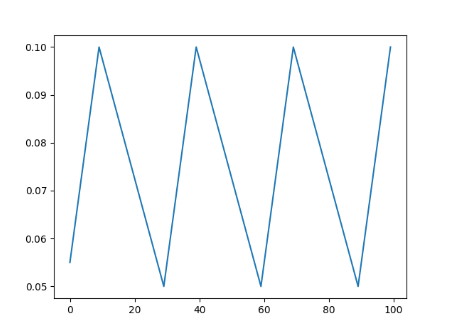
- 循环学习率
恒定的频率循环两个边界之间的学习率
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer,base_lr=0.05,max_lr=0.1,step_size_up=10,step_size_down=20)
-
warm up
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳