martin
并行训练
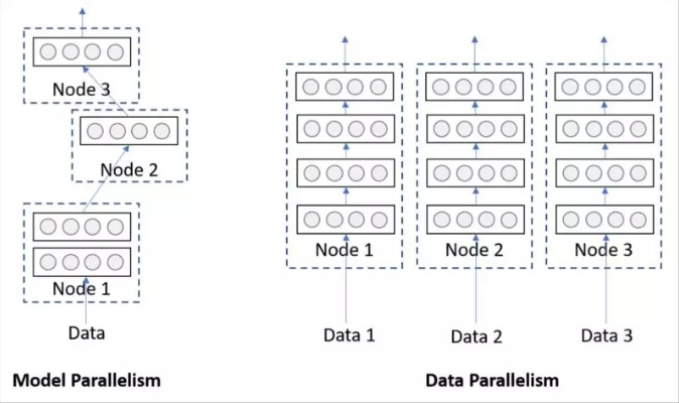
单机多卡的训练,即并行训练,分为数据并行,模型并行两种
-
nn.DataParallel
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
module 模型
device_ids GPU列表,list 或者int 类型,默认全部GPU
output_device 输出的GPU, 默认使用第一个 device_ids[0]
pytorch 默认使用一张卡,采用并行训练之后可以采用多卡,DataParallel 是并行训练一种
import os
import torch
# 定义物理上可用的卡
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
# 数据一般加载在第一张卡,第一张卡占用率会高一点,model参数和data会复制共享到其他卡上
device = torch.device("cuda:0")
# 定义逻辑上的可用卡 物理卡两块 在逻辑上为0,1
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)
model.to(device)
# 数据分发到其他卡上
data.to(device)
其他方法以后使用到在进行添加
[Reference]