martin
MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
这篇论文的核心应该是提出深度可分离卷积,大大降低计算量
1 可分离卷积
可分离卷积的提出是在这篇论文中Simplifying ConvNets for Fast Learning,形式如下
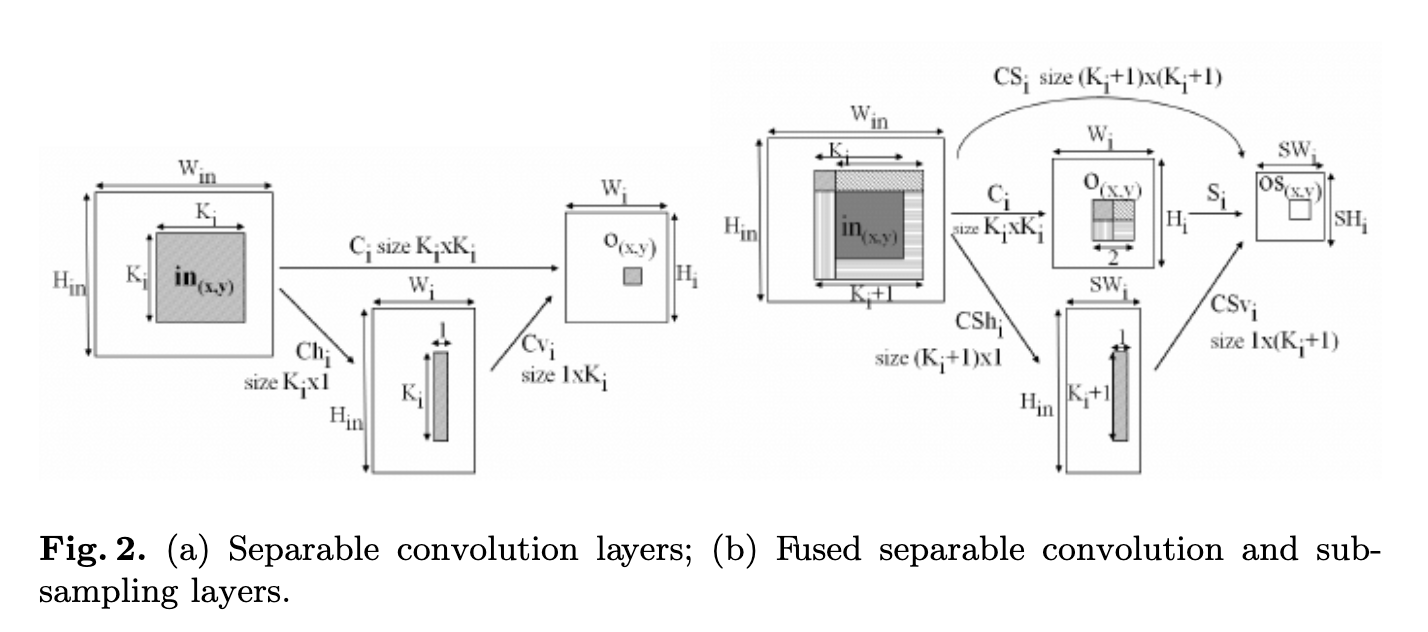
Laurent Sifre博士2013年在谷歌实习期间,将可分离卷积拓展到了深度(depth),并且在他的博士论文Rigid-motion scattering for image classification中有详细的描写
可分离卷积主要分两种,深度可分离卷积和空间可分离卷积
1.1 空间可分离卷积
空间可分离就是将一个大的卷积核变成两个小的卷积核,比如将一个33的核分成一个31 和一个 1*3 的核
\[\begin{bmatrix} 1 & 2 & 3 \\ 0 & 0 & 0 \\ 2 & 4 & 6 \end{bmatrix} = \begin{bmatrix} 1 \\ 0 \\ 2 \end{bmatrix} * \begin{bmatrix} 1 & 2 & 3 \end{bmatrix}\]详细内容可以去看看论文,不多讲
1.2 深度可分离卷积
深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions)。其可以分解为两个更小的操作:depthwise convolution 和 pointwise convolution。
图片大部分来源博客卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3) - 战争热诚 - 博客园 (cnblogs.com)
1.2.1 标准卷积
输入一个12*12*3的一个输入特征图,经过 5*5*3的卷积核得到一个8*8*1的输出特征图。如果我们此时有256个特征图,我们将会得到一个8*8*256的输出特征图
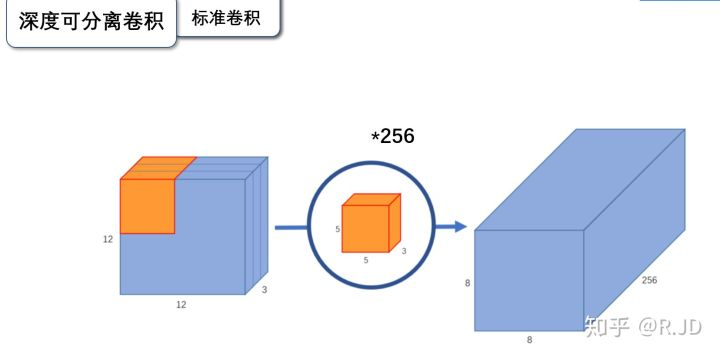
下面这张图描述得更加清晰
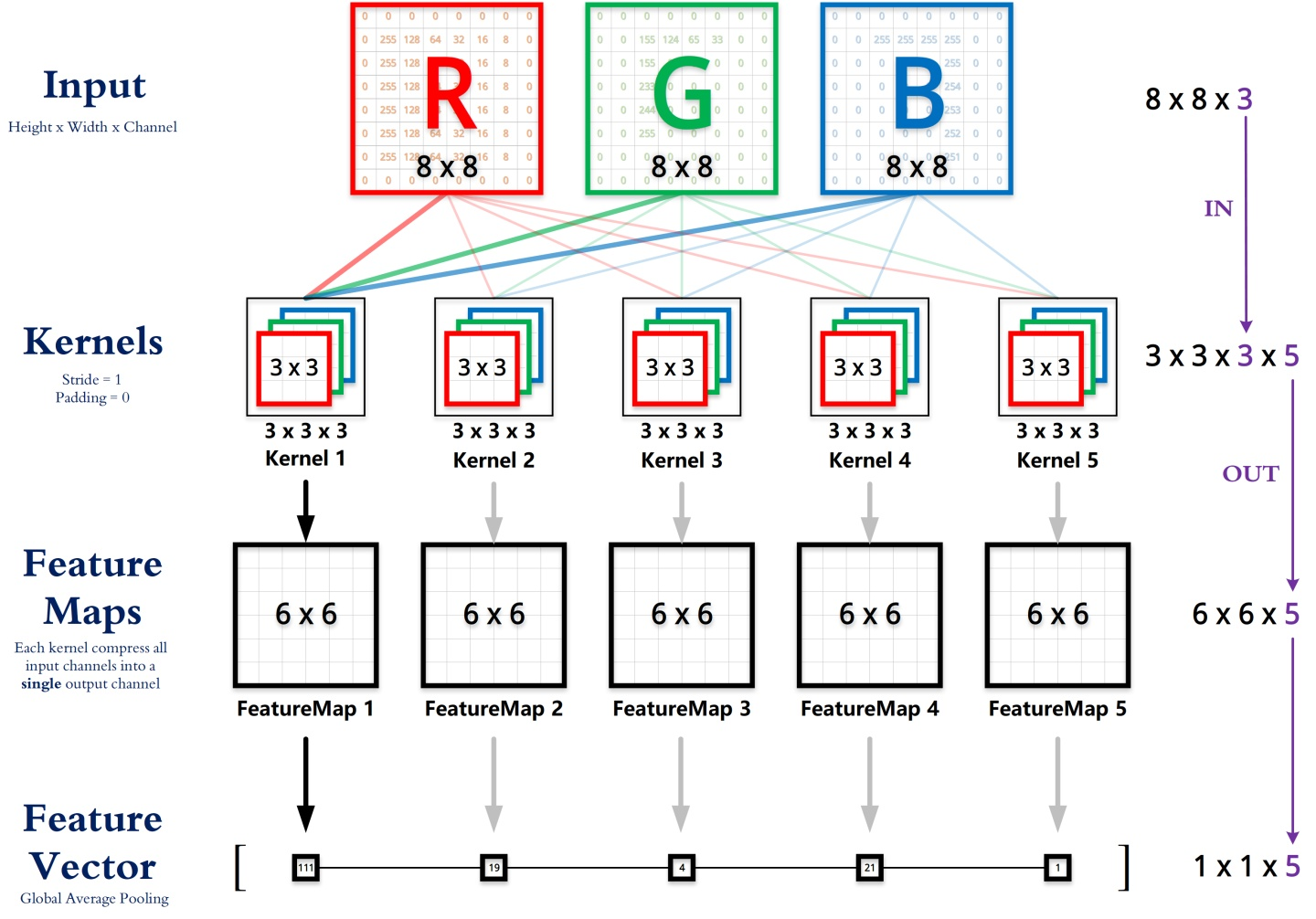
1.2.2 深度可分离卷积
深度卷积(depthwise convolution)
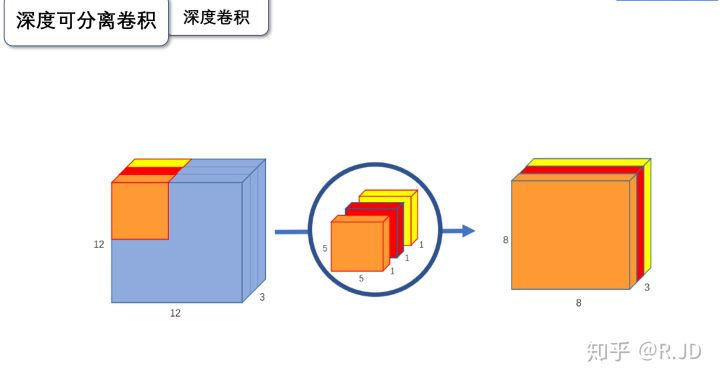
输入12*12*3 的特征图,经过5*5*1*3的深度卷积之后,得到了8*8*3的输出特征图。输入和输出的维度是不变的3,这样就会有一个问题,通道数太少,特征图的维度太少,
逐点卷积
先看一下1*1逐点卷积,pointwise convolution和传统卷积一样,只不过卷积核的大小是1*1,可以升维也可以降维。
深度卷积的过程中,我们得到了883的输出特征图,我们用256个1*1*3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是8*8*256了。

1.3 区别
想要输出同样的维度,传统卷积只需要一步就可以做到,深度可分离卷积需要两步

传统卷积和可分离卷积区别手绘图,来源 轻量级网络–MobileNet论文解读_DFan的NoteBook-CSDN博客
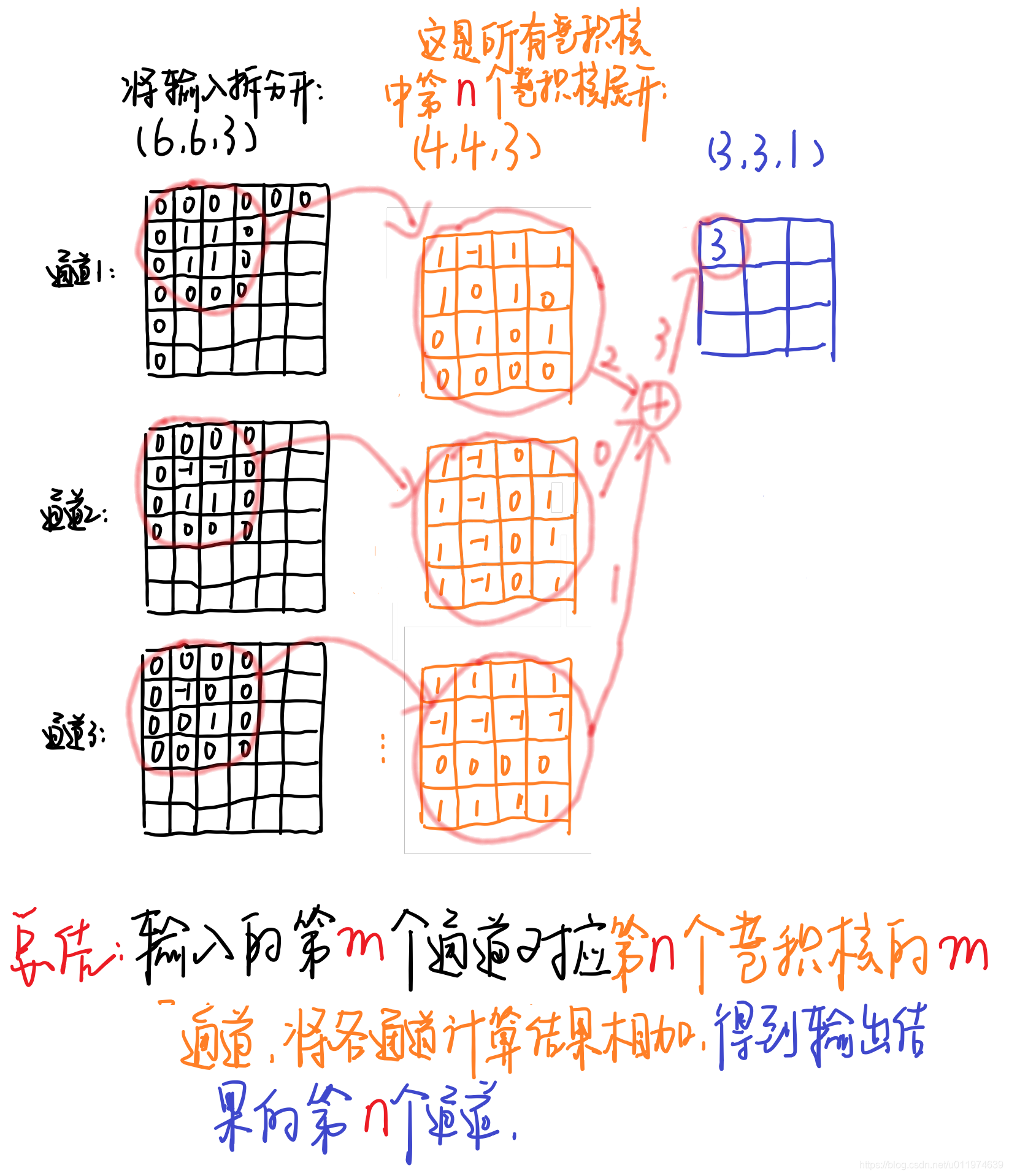
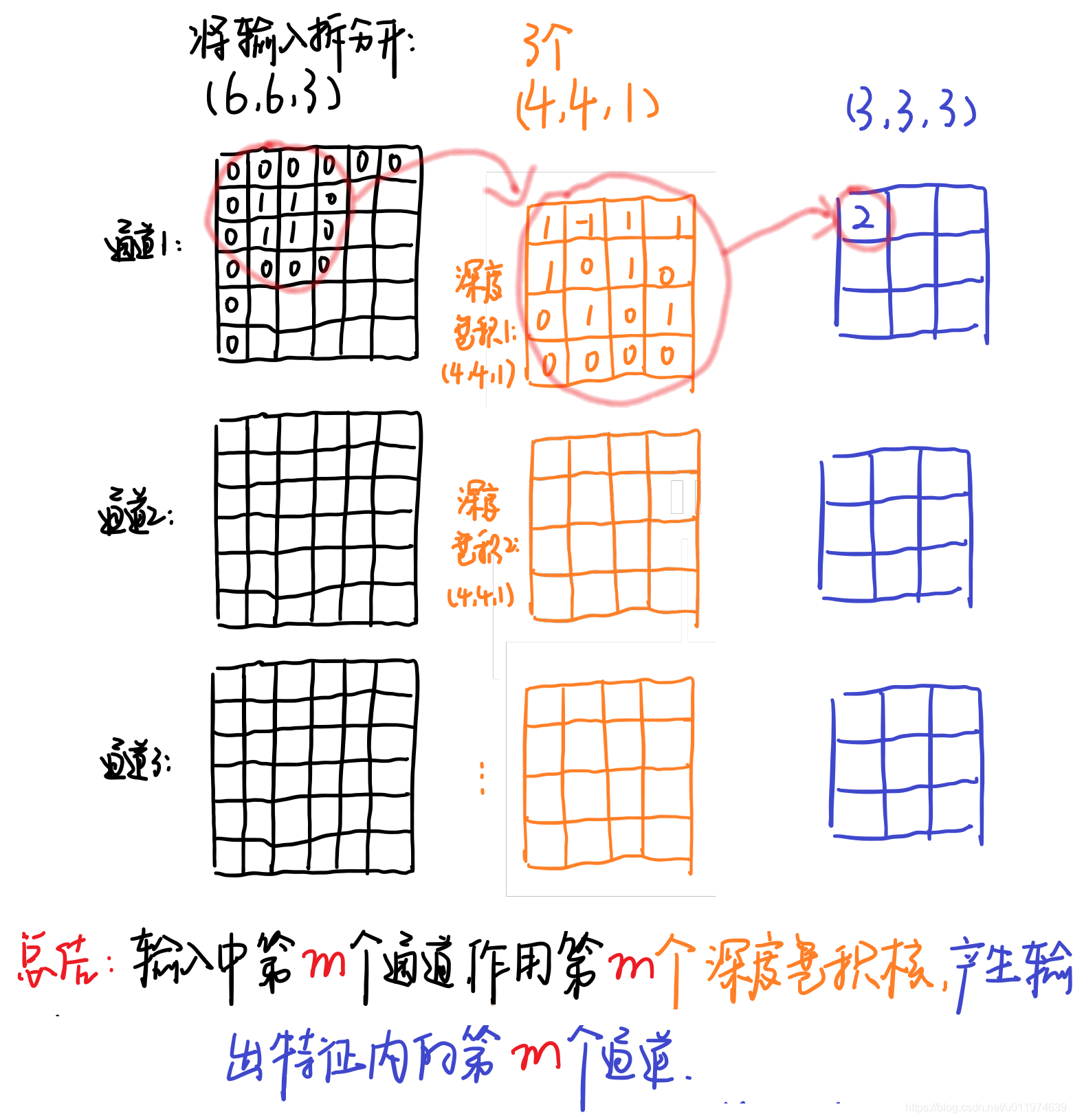
1.4 计算量
深度可分离卷积并非平白无故增加这一步,通过这一步可以有更少的参数,更少计算量,而效果却能达到跟以前差不多的效果
1.4.1 传统卷积计算量
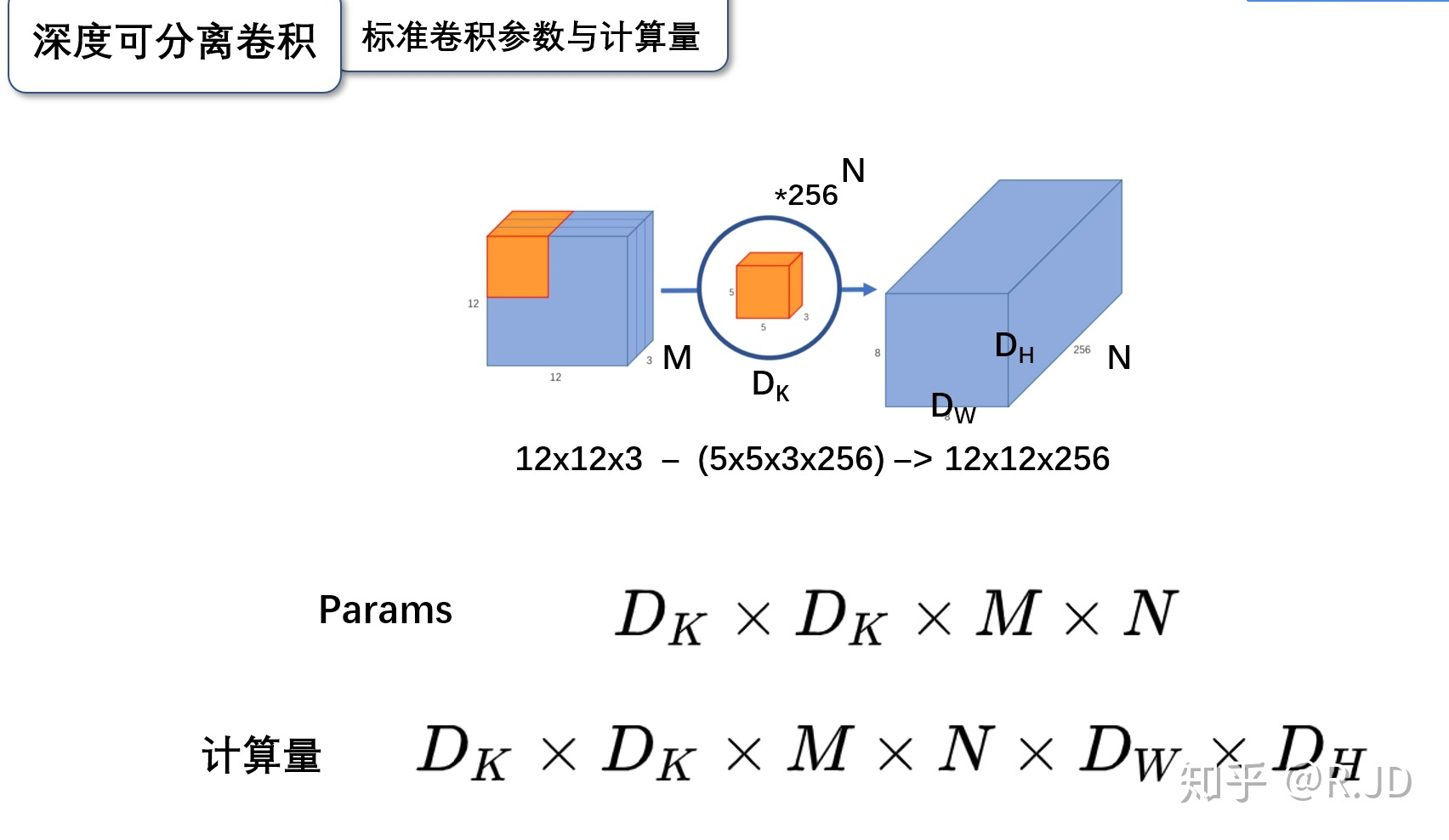
按照原论文中的计算方式, 几个参数的含义可以按照图片理解
参数量:
\[D_{K}*D_{K}*M*N\]计算量:
\[D_{K}*D_{K}*M*N*D_{W}*D_{H}\]1.4.2 深度可分离卷积计算量
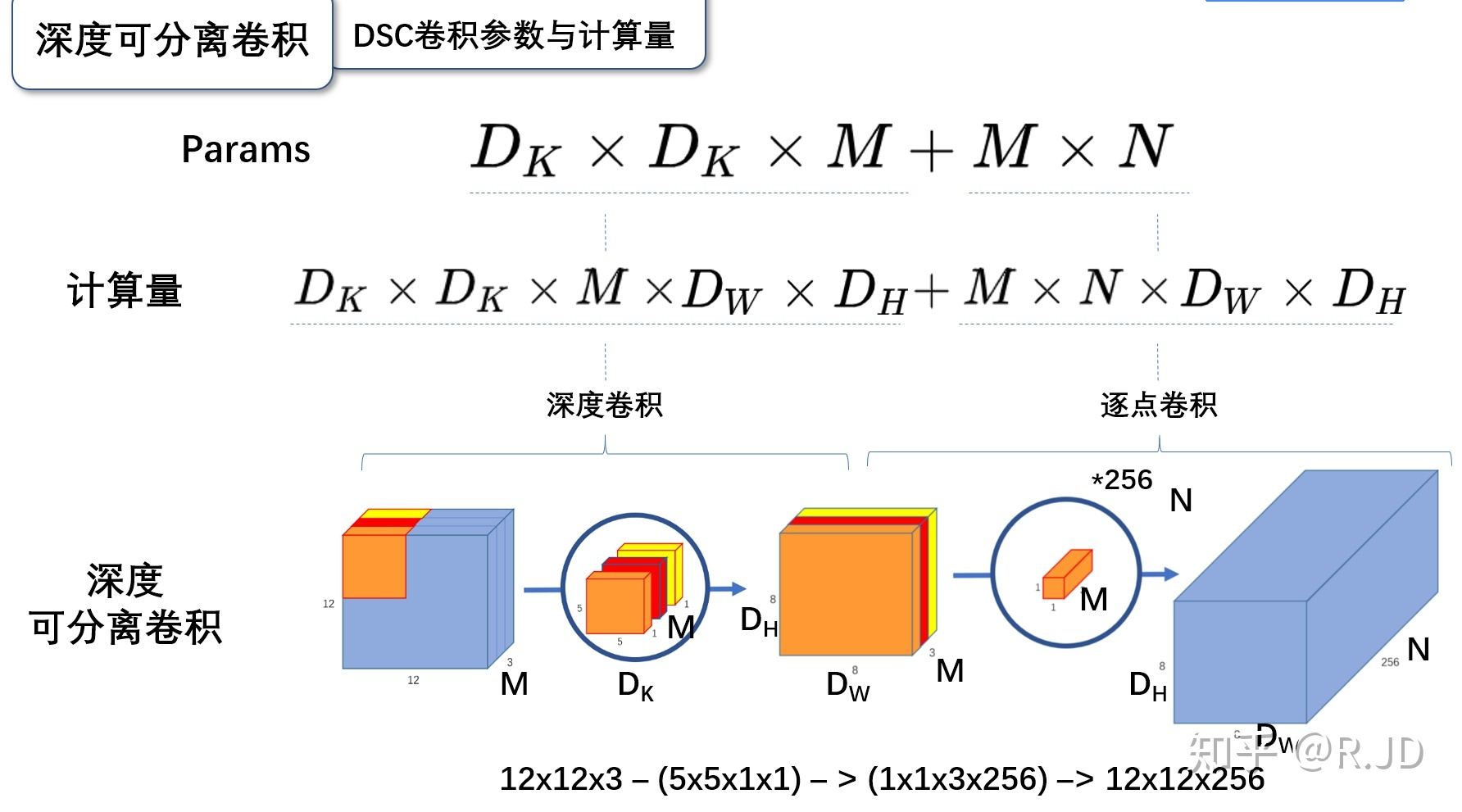
参数量:
\[D_{K=3}*D_{K=3}*M*N_{c=1} + D_{K=1}*D_{K=1}*M*N\]所以简化为图片公式
计算量:
\[D_{K=3}*D_{K=3}*M*N_{c=1}*D_{W}*D_{H} + D_{K=1}*D_{K=1}*M*N*D_{W}*D_{H}\]1.4.3 计算量比较
\[\frac{D_{K}*D_{K}*M*N}{D_{K=3}*D_{K=3}*M*N_{c=1} + D_{K=1}*D_{K=1}*M*N}= \frac{D_{K}*D_{K}*M*N*D_{W}*D_{H}}{D_{K=3}*D_{K=3}*M*D_{W}*D_{H} + M*N*D_{W}*D_{H}}= \frac{1}{N}+\frac{1}{D^{2}_{K=3}}\]通常卷积核采用3*3 , 计算量降低九分之一左右
2 MobileNet
2.1 创新点
2.1.1 组合结构
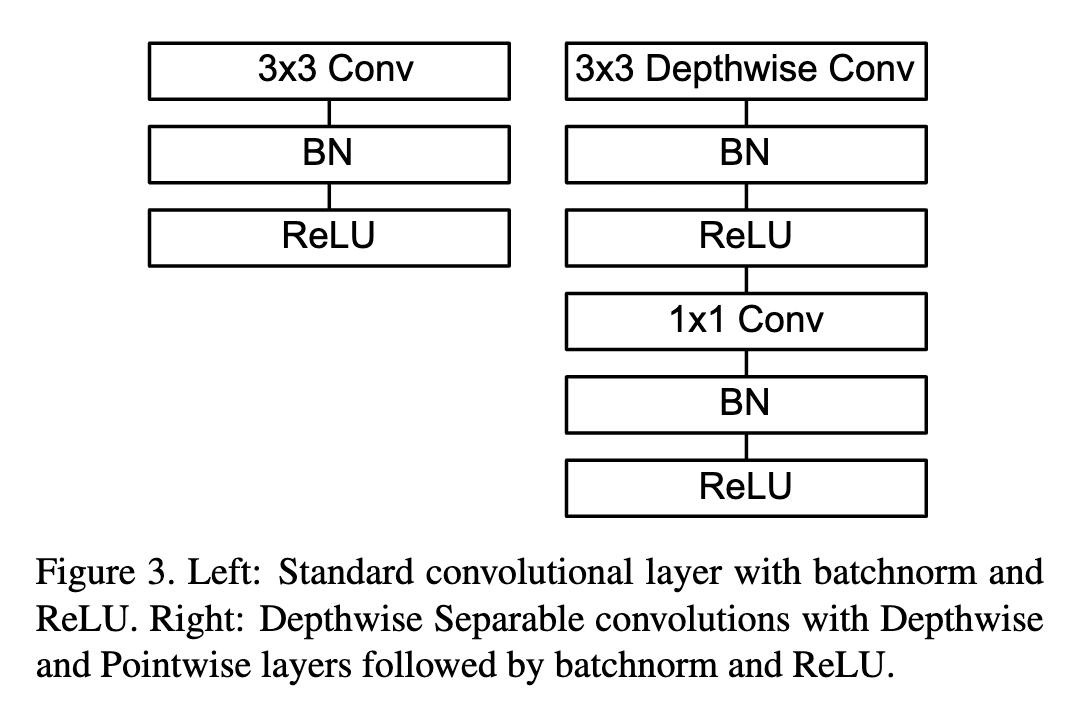
传统卷积是 Conv -> BN -> Relu
MobileNet提出新型组合方式 DWConv -> BN -> Relu -> PWConv -> BN -> Relu
后续很多轻量型网络也是大体这个结构
2.1.2 Relu6
MobileNet 中使用了ReLU6作为激活函数,这个激活函数在 float16/int8 的嵌入式设备中效果很好,能较好的保持网络的鲁棒性。更多的ReLU6,增加了模型的非线性变化,增强了模型的泛化能力。
图像后续补充
ReLU6 就是普通的ReLU,但是限制最大输出值为6(对输出值做 clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失.
2.1.3 Width Multiplier: Thinner Models
宽度因子 alpha (Width Mutiplier)在每一层对网络的输入输出通道数进行缩减,输出通道数由 M 到 alpha*M,输出通道数由 N 到 alpha*N,变换后的计算量为:
\[D_{K=3}*D_{K=3}*\alpha M*N_{c=1}*D_{W}*D_{H} + D_{K=1}*D_{K=1}*\alpha M*N*D_{W}*D_{H}\]分辨率因子 rho (resolution multiplier)用于控制输入和内部层表示,即用分辨率因子控制输入的分辨率,深度卷积和逐点卷积的计算量为
\[D_{K=3}*D_{K=3}*\alpha M*N_{c=1}* \rho D_{W}* \rho D_{H} + D_{K=1}*D_{K=1}*\alpha M*N* \rho D_{W}* \rho D_{H}\]2.2 网络架构
MobileNet网络架构是比较清晰明了的,通过基本小模块组装的基本模块conv dw组成,整个模型是一个流线型,一共由 28层构成(不包括AvgPool 和 FC 层,且把深度卷积和逐点卷积分开算),其除了第一层采用的是标准卷积核之外,剩下的卷积层都是用Depth Wise Separable Convolution, 具体参数如下表

3 总结
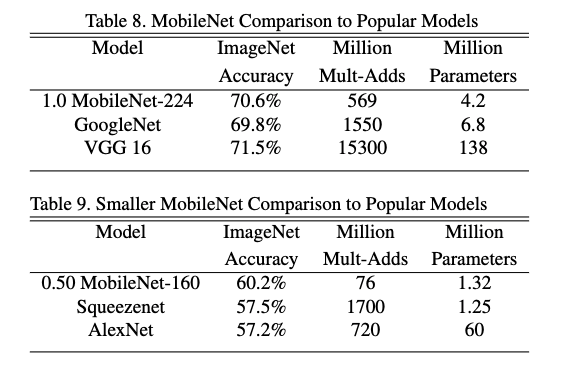
这里给出一张原论文中的参数量和准确率对比图,可以看到在参数明显减少的情况下,准确度并没有下降多少
暂时更新到这里,后续继续更新