martin
MobileNetV2
很明显是对一代的改进,论文地址MobileNetV2: Inverted Residuals and Linear Bottlenecks (arxiv.org)
V1问题
Depthwise Separable Convolutions
MobileNet V1 的结构较为简单,另外,主要的问题还是在Depthwise Convolution 之中,Depthwise Convolution 确实降低了计算量,但是Depthwise部分的 Kernel 训练容易废掉,即卷积核大部分为零,作者认为最终再经过 ReLU 出现输出为 0的情况
作者对此的解释为
when ReLU collapses the channel, it inevitably loses information inthat channel. How-ever if we have lots of channels, and there is a structure in the activation manifold that information might still bepreserved in the other channels.
ReLU 会对 channel 数较低的张量造成较大的信息损耗, 可能会让激活空间坍塌,不可避免的会丢失信息,简单来说,就是当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示:

V2改进
高维信息变换回低维度信息时,相当于做了一次特征压缩,会损失一部分信息,再进行ReLU后,损失的部分就更大了
Inverted Residuals
上面前半句可以理解为,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少
针对这个问题,对比V1
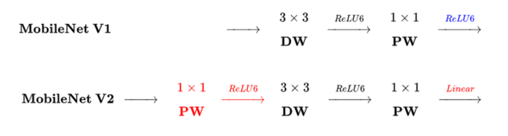
选择先升维 -> 卷积 -> 降维, 这样解决第一个问题
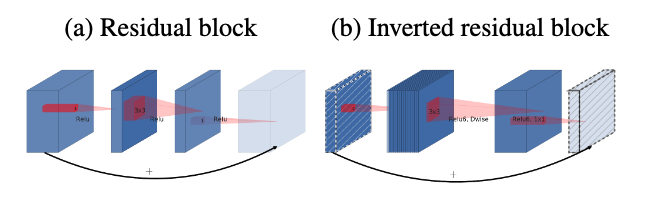
- 残差模块:输入首先经过1*1的卷积进行压缩,然后使用33的卷积进行特征提取,最后在用11的卷积把通道数变换回去。整个过程是“压缩-卷积-扩张”。这样做的目的是减少3*3模块的计算量,提高残差模块的计算效率。
- 倒残差模块:输入首先经过1*1的卷积进行通道扩张,然后使用3*3的depthwise卷积,最后使用1*1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为6。
Linear Bottleneck
后半句在说 Relu 会损失更多的信息,将最后一层的ReLU替换成线性激活函数,而其它层的激活函数依然是ReLU6,即可保留更多的信息
经过上述的处理之后,引用论文中深度可分离卷积进化过程,可以看到经过上述两个更新后,我们的深度可分离卷积最终样子
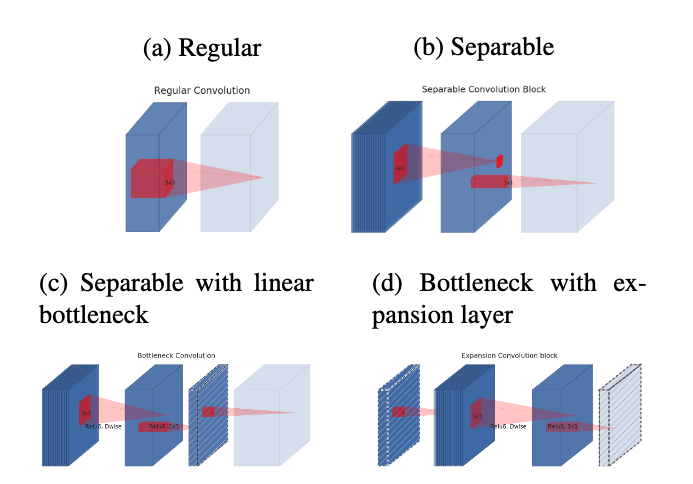
对比

上面图片是论文给出的深度可分离卷积进化过程,v2仍然使用 v1 提出 bottleneck layer 、Expansion layer 方式,在这个基础上更新了以上两点,用来解决训练中卷积核废掉的情况。
结构
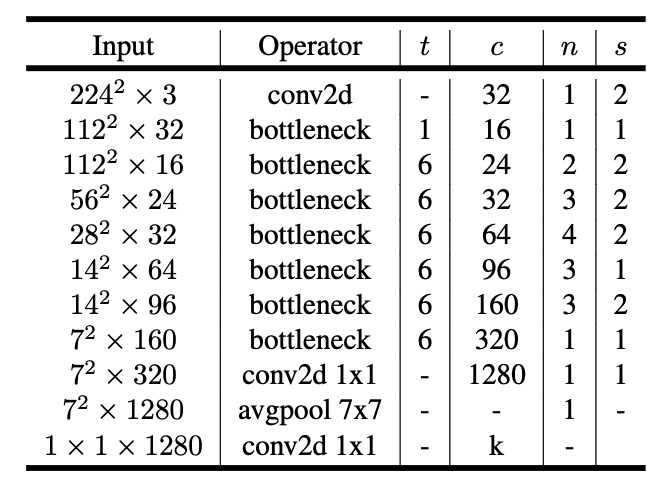
依据论文中V2的网络结构。其中,t 为扩张稀疏,c 为输出通道数,n 为该层重复的次数,s为步长。 V2 网络比V1网络深了很多,V2有54层
在实际使用中,v2效果和速度也比v1要快一些