martin
Robust High-Resolution Video Matting with Temporal Guidance
2021.08
一篇视频扣像论文,实时性很不错,效果不知道怎么样
RVM: Robust High-Resolution Video Matting with Temporal Guidance (peterl1n.github.io)
介绍
神经模型用于解决这个具有挑战性的问题,但当前的解决方案并不总是稳健的,并且经常会产生伪影。我们的研究重点是提高此类应用的消光质量和稳健性
当前扣像个人感觉就是速度和精度的熊和鱼掌不可兼得,单帧图片扣的很完美确实不用担心合成视频的质量,但质量太慢只能适合后期。所以我感觉单纯用处理图片的方法去处理视频是不合适的,视频可能需要其他更有效的方法
带有时间信息的新模型
论文也描述了时间信息会影响视频抠图效果,原因有三点
-
首先,它允许预测更一致的结果,因为模型可以看到多个帧及其自己的预测。这显着减少了闪烁并提高了感知质量。因为视频是连贯的,所以也就是让临近的几帧更接近。
- 其次,时间信息可以提高抠图鲁棒性。在单个框架可能不明确的情况下,例如前景颜色变得类似于背景中经过的物体,模型可以通过参考前一帧更好地猜测边界。当模型面对那些难以区分前背景的画面,可以参考其他帧,有更多的信息去做判断。
- 第三,时间信息允许模型了解更多关于时间背景的信息。当相机移动时,由于视角变化,被摄对象背后的背景会暴露出来。更好地了解背景可以简化抠图任务。提供更多的背景信息给模型
新的训练策略
我们提出了一种新的训练策略,以同时在抠图和语义分割目标上强制执行我们的模型。
这些样本通常看起来是假的,并阻止网络泛化到真实图像。之前的工作 [18, 22] 尝试使用在分割任务上训练的权重来初始化模型,但该模型在抠图训练期间仍然过拟合到合成分布。其他人尝试在未标记的真实图像上进行对抗训练 [34] 或半监督学习 [18] 作为额外的适应步骤。我们认为人类抠图任务与人类分割任务密切相关。与分割目标同时训练可以有效地调节我们的模型,而无需额外的适应步骤。
在 BGMV2 中预训练权重采用分割数据集的,而在MODNet中采用SOC策略去拟合真实世界的数据集。这些方法归根结底还是在合成数据集上做的操作。论文采用与分割目标同时训练可以有效地调节我们的模型,而无需额外的适应步骤。
相关工作
Trimap-based matting
经典的扣像方法,需要一张trimap,使用起来还是比较麻烦
为了将其扩展到视频,Sunet al。提出的 DVM [39],它只需要在第一帧上有一个trimap,并且可以将其传播到视频的其余部分。
Background-based matting
此信息充当前景选择的隐式方式,并提高了抠图的准确性。林和 Ryabtsevet al。进一步提出了 BGMv2 [22],具有改进的性能和对实时高分辨率的关注。但是,backgroundmatting 无法处理动态背景和大型摄像机时代的运动。
需要背景的扣像方式,背景只能是固定的,可以理解为前景背景区分的方法。
Segmentation
语义分割是为每个像素预测一个类标签,通常不需要辅助输入。它的二值分割掩码可以用来定位人类主体,但直接使用它进行背景替换会产生很强的伪影
语义分割的输出非0即1,而matting输出是0-255
Auxiliary-free matting
也就是无任何辅助,真正全自动抠图,而且方法鲁棒性很好。
Video matting
很少有神经抠图方法是为视频原生设计的。 MODNet [18] 提出了一种后处理技巧,可以比较相邻帧的预测以抑制闪烁,但它无法处理快速移动的身体部位,并且模型本身仍然作为独立图像在帧上运行。 BGM [34] 探索了将几个相邻帧作为附加输入通道,但这仅提供短期时间线索,其效果不是研究的重点。 DVM [45] 是视频原生的,但专注于利用时间信息来传播trimap 注释。相反,我们的方法侧重于使用时间信息来提高无辅助设置中的抠图质量。
这是很重要的一点,这个方法首先就是针对视频扣像做的
Recurrent architecture
循环神经网络已广泛用于序列任务。两种最流行的架构是 LSTM(长短期记忆)[13] 和 GRU(门控循环单元)[6],它们也被用于视觉任务,如 ConvLSTM [36] 和 Con-vGRU [2] .以前的工作探索了将循环架构用于各种视频视觉任务,并显示出与基于图像的对应部分相比性能有所提高 [42, 28, 41]。我们的工作采用循环架构来处理抠图任务
这是创新点,将RNN的方式放到视频扣像中
High-resolution matting
PointRend [19] 已经探索了基于补丁的细化用于分割和 BGMv2 [22] 用于抠图。它只对选择性补丁执行卷积。另一种方法是使用 Guided Fil-ter [11],这是一种后处理滤波器,可以在给定高分辨率帧指导的情况下对低分辨率预测进行联合上采样。 Deep Guided Filter (DGF) [44] 被提出作为一个可学习的模块,可以在没有手动超参数的情况下通过网络进行端到端的训练。尽管基于过滤器的上采样功能不那么强大,我们还是选择了它,因为它速度更快,并且得到所有推理框架的良好支持
这是另一个创新点,降低分辨率可以提取到相同的特征,但计算量却可以惊人的下降
Model Architecture
我们的架构由一个提取单个帧特征的编码器、一个聚合时间信息的循环解码器和一个用于高分辨率上采样的深度引导滤波器模块组成。图 2 显示了我们的模型架构
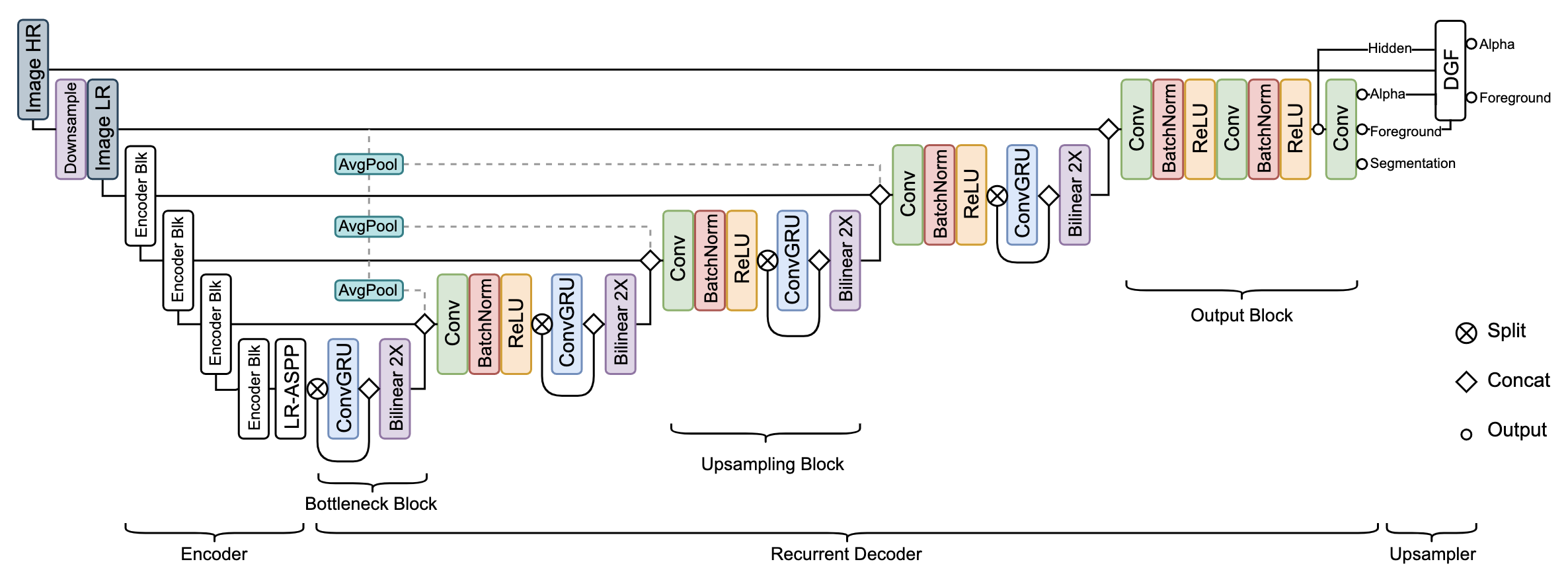
Feature-Extraction Encoder
MobileNetV3做为主干,Noticeably, the last block of MobileNetV3 uses dilated convolutions without downsampling stride
使用 1/2 1/4 1/8 1/16 的特征,后面跟一个LR-ASPP
LR-ASPP
这个模块是MobileNetV3论文中提出用来做分割的一个模块
Recurrent Decoder
出于多种原因,我们决定使用循环架构而不是注意力机制或简单地将多个帧前馈作为额外的输入通道。循环机制可以在连续的视频流上自行学习要保留和忘记哪些信息,而其他两种方法必须依靠固定规则在每个设置间隔上将旧信息删除并插入新信息到有限的内存池。自适应地保留长期和短期时间信息的能力使循环机制更适合我们的任务
与以前的模型大致相同,采用跳级链接和上采样的方法,不同在于多了一层 ConvGRU,这个算子可以获得时间和空间上的信息,这个算子后期会详细讲解
Bottleneck block
在1/16的比例下,encoder 的 lraspp 后接这个模块,这里是直接对 1/16 比例进行处理,所以直接加 ConvGRU 和 Bilinear . 具体操作在下面代码中列出来
class BottleneckBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.channels = channels
self.gru = ConvGRU(channels // 2)
def forward(self, x, r: Optional[Tensor]):
a, b = x.split(self.channels // 2, dim=-3)
b, r = self.gru(b, r)
x = torch.cat([a, b], dim=-3)
return x, r
Upsampling block
Conv+BN+ReLU 的组合,输入是经过 cat 的上一级下采样以及下一级双线性上采样。
后面在跟一个 ConvGRU层,这里处理是 applying ConvGRU on half of the channels by split and concatenation effective and efficient,作者解释为 这种设计有助于 ConvGRU 专注于聚合时间信息,而另一个拆分分支则转发特定于当前帧的空间特征
这个模块分别添加在1/8 1/4 1/2 的特征图中
Output block
we find it expansive and not impactful at this scale. 我所理解这句话就是输出部分在这种规模下采用 ConvGRU 会付出昂贵的代价,并且效果还不尽如意。所以这里采用常见的 Conv+BN+RELU 操作
it can be given T frames at once as input and each layer processes all T frames before passing to the next layer.
这里补充代码理解上述话
Deep Guided Filter Module
还原到原始分辨率模块,具体描述是 “在通过编码器 - 解码器网络之前,我们通过一个因子对输入帧进行下采样。然后将低分辨率 alpha、前景、最终隐藏特征以及高分辨率输入帧提供给 DGF 模块以生成高分辨率 alpha 和前景。”
这个算子是在另一篇论文中提出,后续可能会补充一下
这个地方在这篇论文中更像是一个插件的形式存在,提出这个模块的论文实际是采用引导滤波的方式进行上采样,思想和HDRNet相同,不同的是HDRNet采用的是双边滤波的方式进行上采样
训练
程序训练
这个模型的训练看起来训练是很复杂的,分成四个步骤单独训练,这里就贴一张训练的大概流程

数据集
数据集使用是 VideoMatte240K (VM) [22], Distinctions-646 (D646) [30], Adobe Image Matting(AIM) [45]
分割数据集采用 image segmentation datasets YouTubeVIS(背景是移动的) COCO [23] and SPD [40].
损失函数
训练是在分割数据集和matting数据集同时训练,所以损失分为两大块,semantic segmentation loss 和 matting loss, 说明一下,右上角带星号是ground truth,不带星号是prediction
semantic segmentation loss采用交叉熵损失, segmentation probabil-ity $S_t$ w.r.t. the ground-truth binary label $S^∗_t$
\[L^S=S^*_t(-log(S_t))+(1-S^*_t)(-log(1-S_t))\]matting loss由四个小部分构成
首先是 alpha 采用 L1 loss
\[L^{\alpha}_{l1}=||\alpha_t - \alpha^*_t||_1\]然后是 pyramid Laplacian loss
\[L^{\alpha}_{lap}=\sum^5_{s=1}\frac{2^{s-1}}{5}||L^s_pyr(\alpha_t) - L^s_pyr(\alpha^*_t)||_1\]temporal coherence loss, to reduce flicker 感觉有点像 MODNet 中的一个后处理操作
\[L^{\alpha}_{tc}=||\frac{d\alpha_t}{dt} - \frac{d\alpha^*_t}{dt}||_2\]To learn foreground,上面是对alpha的学习,下面是对合成前景的损失
同样是 L1 损失
\[L^F_{l1}=||(\alpha^*>0)*(F_t - F^*_t)||_1\]同样有一个 temporal coherence loss
\[L^{F}_{tc}=||\frac{dF_t}{dt} - \frac{dF^*_t}{dt}||_2\]总损失就是他们相加,不过两个 temporal coherence loss 的系数是5,增大这个损失
Experimental Evaluation
实验的效果图片就不多放了,感兴趣可以去论文里面查看效果,这里贴出该算法与其他算法的对比情况
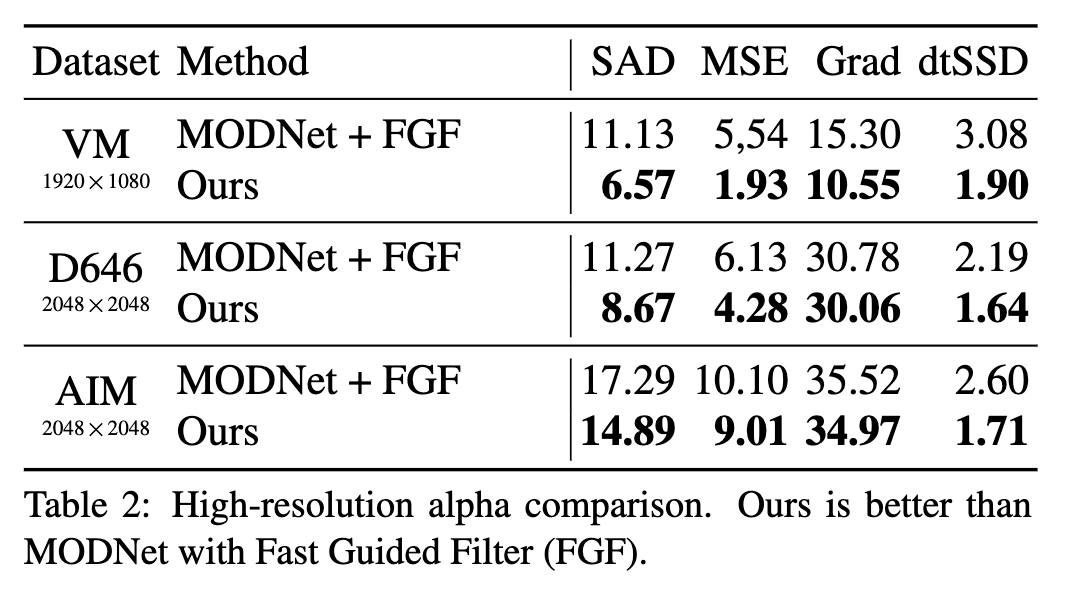
FGF也就是上采样还原模块,这里主要对比是 MODNet ,可以看到各方面提升很明显,我以前也用过MODNet, 效果确实不是很好,人像扣取并不完整
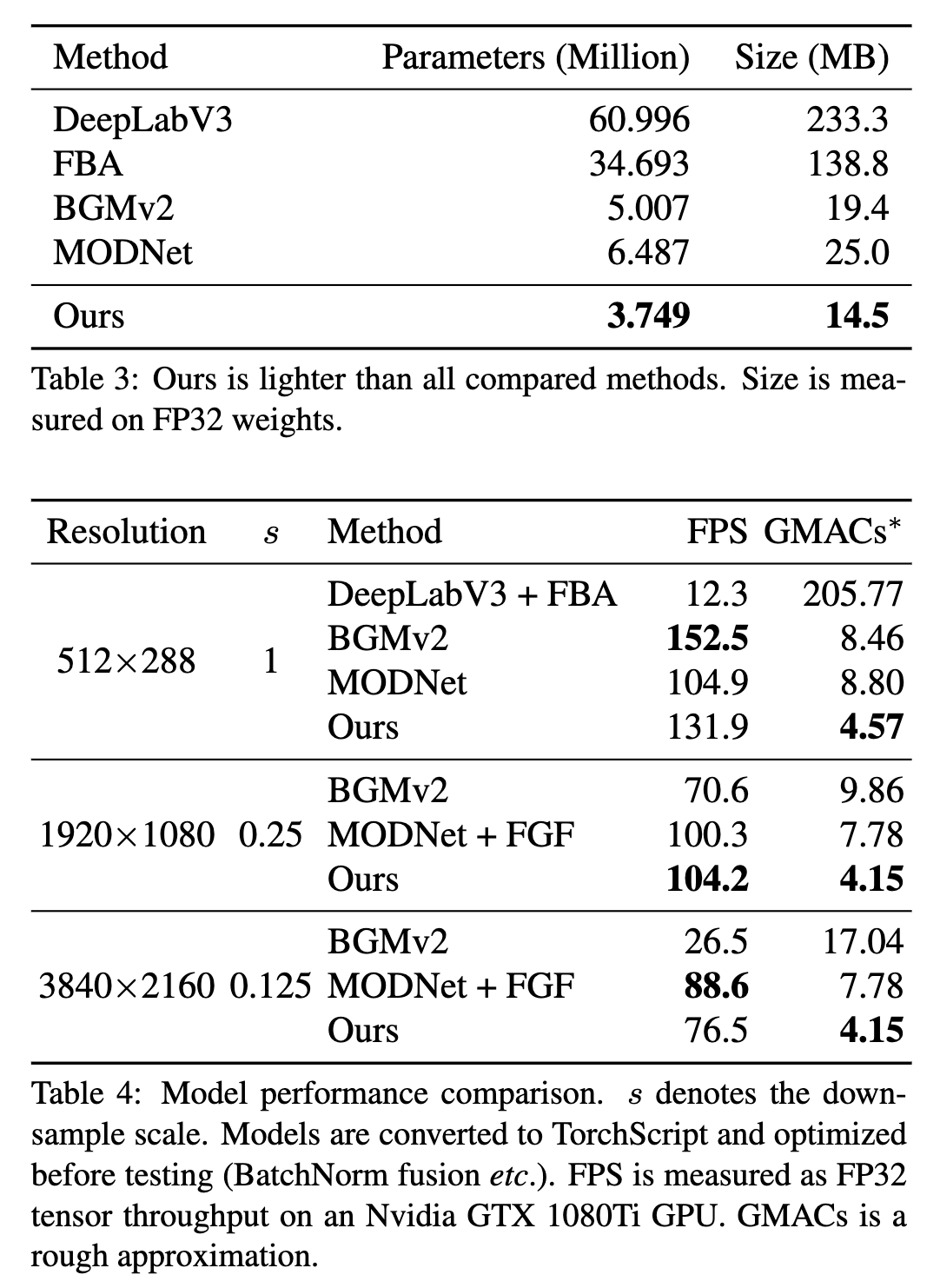
这部分是速度的对比,实时扣像中效果和MODNet的对比效果,1080P的时候RVM的FPS最高
Ablation Studies
这个部分作者对上述的几个模块进行消光实验,并解释说明这个模块的重要性
Role of Temporal Information
时间信息模块的作用首先是消除闪烁,MODNet尽管可以达到实时,但是使用过程中会出现闪烁很严重的情况。“我们进一步检查循环隐藏状态。在图 6 中,我们发现我们的网络已经自动学会了随着时间的推移而重建背景,并将这些信息保留在其循环通道中以帮助未来的预测。它还使用其他循环通道来跟踪运动历史。我们的方法甚至尝试在视频包含相机运动时重建背景,并且能够忘记无用的内存镜头剪辑。更多的例子在补充中。”,对于移动的背景 可以很好的重建背景
Role of Segmentation Training Objective
训练的时候和分割一块训练,从而保证算法的稳健,“COCO 验证集上的分割性能。使用分割目标进行训练使我们的方法健壮比起仅使用预训练权重进行训练回归”,分割算法目前发展的非常成熟,结果非常的稳定健壮,在分割的基础上继续改进边缘,达到扣像的效果,理论来说确实可以达到很不错的效果
Role of Deep Guided Filter
“表 6 显示,与 FGF 相比,DGF 仅具有很小的开销和速度。 DGF具有更好的Gradmetric,说明其高分辨率细节更准确。 DGF 还产生由 dtSSD 度量指示的更连贯的结果,可能是因为它考虑了循环解码器的隐藏特征。 MAD 和 MSE 指标是不确定的,因为它们由分段级别的错误主导,而 DGF 或 FGF 都没有纠正这些错误”
论文对这个部分的作用并没有详细阐述,这个部分是改自另一篇论文,这个地方的底层算法就是对结果进行一次上采样,采用非深度学习的方法可以减少计算量
Limitations
“我们的方法更喜欢目标主题明确的视频。当背景中有人时,感兴趣的主题变得模糊。它还支持更简单的背景以产生更准确的抠图。图 7 显示了具有挑战性的案例的示例。”
这也是扣像的一个问题所在,到底什么是前景,什么是背景,单单用数据集来告诉模型前景背景够不够。
这是字节最新开源的一篇论文,看demo效果确实很不错,论文中的各个指标很华丽,通常情况下自己动手实验效果不是很好。但论文有两个亮点,一个就是利用DGF降低计算量,这个和我们最近在做的一个工作类似;另一个亮点就是时间信息的加入,这个模型一开始就是为了视频扣像设计的。这点很值得思考。